
clickhouse存储机制以及底层数据目录分布
在大部分的DBMS中,数据库本质上就是一个由各种子目录和文件组成的文件目录,clickhouse当然也不例外。clickhouse默认数据目录在/var/lib/clickhouse/data目录中。所有的数据库都会在该目录中创建一个子文件夹。下图展示了clickhouse对数据文件的组织。
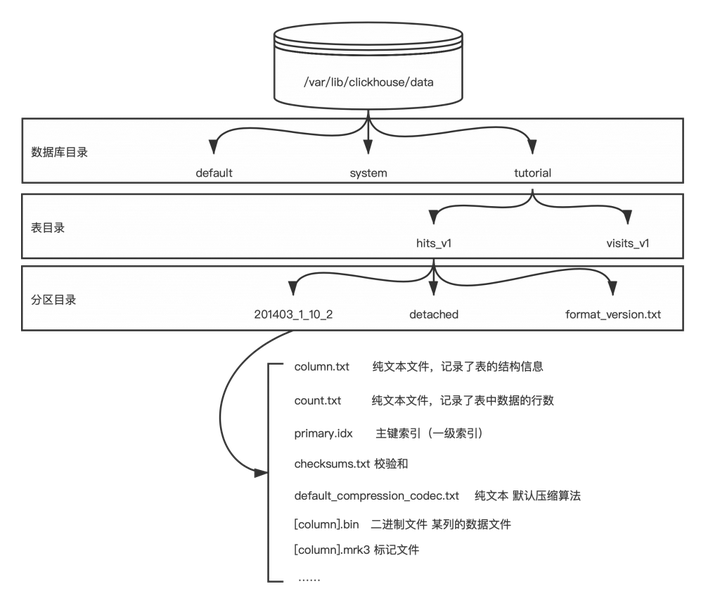
每一个数据库都会在clickhouse的data目录中创建一个子目录,clickhouse默认携带default和system两个数据库。default顾名思义就是默认数据库,system是存储clickhouse服务器相关信息的数据库,例如连接数、资源占用等。
分区目录
分区目录下的子目录和文件的含义如下:
| 目录名 | 类型 | 说明 |
|---|---|---|
| 202103_1_10_2 | 目录 | 分区目录一个或多个,由于分区+LSM生成的 |
| detached | 目录 | 通过DETACH语句卸载后的表分区存放位置 |
| format_version.txt | 文本文件 | 纯文本,记录存储的格式 |
分区目录构成
分区目录的构成,按照 分区ID_最小数据块编号_最大数据块编号_层级构成。在本例中,分区ID是202103,最小数据块编号是1,最大数据库编号是10,层级是2。数据块编号从1开始自增,新创建的数据库最大和最小编号相同,当发生合并时会将其修改为合并的数据块编号。同时每次合并都会将层级增加1。
分区ID由用户在创建表时制定,允许用户创建多个分区键,每个分区键之间用‘-’相连。在本例中只使用了一个分区键,即时间字段,按照年月分区。分区的好处在于提高并发度和加速部分查询。
数据目录
进入分区目录后,就能看到数据真实存储的数据目录的结构了。
columns.txt
该文件是一个文本文件,存储了表结构信息,可以用文本编辑打开。
count.txt
该文件也是一个文本文件,存储了该分区下的行数。可以用文本文件打开。在用户执行select count() from xxx时本质上就是直接返回了该文件的内容,而不需要遍历数据。因此clickhouse的count()的速度非常快。
同时,这边也对比一下MySQL和PostgreSQL的实现,在上述两个关系型数据库中,其常用的存储引擎,都没有使用clickhouse的这种方案。读者们能否回答出为了MySQL或pg要舍弃简单的方案而使用遍历么?
这个问题的答案是由于事务的可见性,MySQL和pg都是用MVCC机制的事务控制技术,这意味着对于不同事务中执行select count(*)的结果是不同的,对于A事务中执行的insert或delete,对于本事务中是可见的,也就是说在本事务中执行的count是计算了insert和delete影响的。而对于B事务,在A事务提交前,是不能看到A事务中对数据的操作的。因此AB两个事务中执行的count后的结果可能是不同的。如果使用clickhouse的方案,就无法实现上述需求。而clickhouse则不需要支持事务,因此使用了相对简单的方案。
primary.idx
主键索引
checksums.txt
二进制文件
default_compression_codec.txt
新版本增加的一个文件,在旧版本时无。该文件是一个文本文件,存储了数据文件中使用的压缩编码器。clickhouse提供了多种压缩算法供用户选择,默认使用LZ4。
[column].mrk3
列的标记文件
[column].bin
真正存储数据的数据文件。每一列都会生成一个单独的bin文件。
skp_idx_[column].idx
跳数索引,在使用了二级索引时会生成,否则这不生成。
skp_idx_[column].mrk
跳数索引标记文件,在使用了二级索引时会生成。否则这不生成
数据组织
如何读取bin文件。由于bin文件是二进制文件,在读取时需要借助工具,无法使用文本文件进行读取。在windows操作系统下建议使用winhex,mac系统推荐hex friend。
数据文件结构

上图展示了一个bin文件的结构。bin文件使用小端字节序存储。bin文件中按block为单位排列数据,每个block文件有16字节校验和,1字节压缩方式,4字节压缩后大小和4字节的压缩前大小组成。每个block起始地址由如下公式确定:
- offset(n)=offset(n-1)+25+压缩后大小 (n>=2)
- offset(1)=0
校验和
前16为检验和区域用于快速验证数据是否完整。
压缩方式
默认为0x82。clickhouse共支持4种压缩方式,分别为LZ4(0x82)、ZSTD(0x90)、Multiple(0x91)、Delta(0x92)。
压缩后大小
存储在data区域的数据的大小。需要依据此大小计算下一个BLOCK的偏移量。
压缩前大小
data区域存储的数据在压缩前的大小。可以依据此计算压缩比。
data区
data区存储数据,大小为头信息第18~21字节表示的大小。拿到data区数据后,由于是压缩后的,因此无法直接识别,需要按照压缩方式进行解压缩后,才能识别。
